It’s an exciting time to be a software engineer. Building and training neural networks has never been easier thanks to TensorFlow. As fun as TensorFlow is, nobody wants to wait around for a model to train — we need GPU muscle!
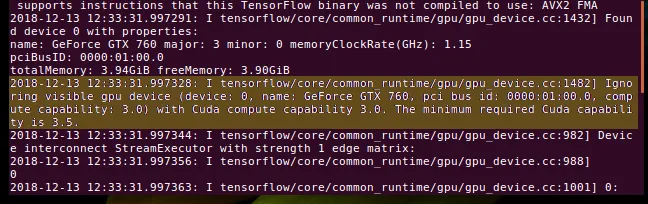
The pre-built releases of TensorFlow are continually updated to target the latest CUDA devices, which is problematic for those of us with older, but still CUDA-enabled, GPUs. What follows is a step by step process for compiling TensorFlow from scratch in order to achieve support for GPU acceleration with CUDA Compute Capability 3.0
Step 0: Install NVIDIA Driver
We are eventually going to install CUDA 9.0, which itself requires NVIDIA driver version 384 or above:
sudo apt-get install -y nvidia-384 nvidia-modprobe
After installing the driver, it’s time for a quick reboot:
sudo reboot
Now, let’s confirm the driver was installed correctly by running nvidia-smi . If your output looks something like below, you are good to move forward.
$ nvidia-smi
Fri Dec 14 00:25:08 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.145 Driver Version: 384.145 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 760 Off | 00000000:01:00.0 N/A | N/A |
| 43% 43C P8 N/A / N/A | 42MiB / 4035MiB | N/A Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX 465 Off | 00000000:02:00.0 N/A | N/A |
| 44% 73C P0 N/A / N/A | 813MiB / 964MiB | N/A Default |
+-------------------------------+----------------------+----------------------+
| 2 GeForce GTX 465 Off | 00000000:03:00.0 N/A | N/A |
| 40% 60C P12 N/A / N/A | 73MiB / 964MiB | N/A Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 Not Supported |
| 1 Not Supported |
| 2 Not Supported |
+-----------------------------------------------------------------------------+
Step 1: Install NVIDIA CUDA
So far, pretty painless — right? Let’s move forward with installing CUDA itself. Per the TensorFlow GPU install guide, let’s install the necessary CUDA toolkit and support libraries:
# Add NVIDIA package repository
sudo apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub
wget http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_9.1.85-1_amd64.deb
sudo apt install ./cuda-repo-ubuntu1604_9.1.85-1_amd64.deb
wget http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1604/x86_64/nvidia-machine-learning-repo-ubuntu1604_1.0.0-1_amd64.deb
sudo apt install ./nvidia-machine-learning-repo-ubuntu1604_1.0.0-1_amd64.deb
sudo apt update
# Install CUDA toolkit and supporting libraries
sudo apt install cuda9.0 cuda-cublas-9-0 cuda-cufft-9-0 cuda-curand-9-0 \
cuda-cusolver-9-0 cuda-cusparse-9-0 libcudnn7=7.2.1.38-1+cuda9.0 \
libnccl2=2.2.13-1+cuda9.0 cuda-command-line-tools-9-0
# Add a symlink to our libcudnn install
sudo ln -s /usr/lib/x86_64-linux-gnu/libcudnn.so.7 /usr/local/cuda-9.0/lib64/
Note: In an earlier version of this guide, I left out the symlink step for libcudnn! If you are getting complaints during the configure step about libcudnn being misplaced, check your symlink.
These steps only get us part of the way. As we are planning to compile TensorFlow from scratch, we will also need to install the dev packages:
# Install the CUDA dev packages sudo apt install cuda-cufft-dev-9-0 cuda-cublas-dev-9-0 cuda-curand-dev-9-0 \ cuda-cusolver-dev-9-0 cuda-cusparse-dev-9-0 cuda-driver-dev-9-0
Next, we need to install the libcudnn library, which NVidia keeps gated behind a login portal. Head over to https://developer.nvidia.com/cudnn, and set up your developer account if necessary. Once you are in, download the cudnn runtime and developer packages, and install them. As long as the version is ~v7, you should be fine.
Step 2: Install & Upgrade Python Packages
Let’s install pip and upgrade it before we install the packages required by TensorFlow:
# Install and upgrade pip $ sudo apt-get install python-pip python-dev $ pip install --upgrade pip
Now that that’s out of the way, let’s install the packages TensorFlow requires:
# Install the required Python packages pip install --user numpy keras_applications keras_preprocessing mock # Install the backport of enum (required by the modern TensorFlow releases) sudo apt-get install -y python-enum34
Step 3: Install Bazel
TensorFlow uses the build tool Bazel to control its builds, so it’s time to install Bazel:
# Install Oracle Java 8 (required by Bazel) sudo apt-get install software-properties-common swig sudo add-apt-repository ppa:webupd8team/java sudo apt-get update sudo apt-get install oracle-java8-installer # Install Bazel itself sudo apt-get install -y wget wget https://github.com/bazelbuild/bazel/releases/download/0.19.1/bazel-0.19.1-installer-linux-x86_64.sh chmod +x ./bazel-0.19.1-installer-linux-x86_64.sh ./bazel-0.19.1-installer-linux-x86_64.sh
So far, everything should have been pretty straightforward. Unfortunately, things get messier as we wade into the actual compiling of TensorFlow.
Step 4: Compile & Install TensorFlow
Alright, before we begin, take a deep breathe. Compiling TensorFlow takes a VERY long time, and any issues that may occur are likely to occur here.
Ready? Let’s start by cloning TensorFlow and checking out release version r1.12 . (If you’d like to try your hand at a different version, you’ll need to go to the TensorFlow GitHub repository and find the appropriate commit hash.)
# Clone TensorFlow git clone https://github.com/tensorflow/tensorflow # Check out r1.12 cd tensorflow git reset --hard a6d8ffae097d0132989ae4688d224121ec6d8f35
Next up is to run ./configure. The choice of configuration settings here is pretty important, so I’ll step through them with you carefully.
WARNING: The following rc files are no longer being read, please transfer their contents or import their path into one of the standard rc files: [...]/tensorflow/tools/bazel.rc
Aren’t we off to a strong start! Don’t sweat this error, we will address it in later steps. For the next few options, let’s just accept the default suggestions:
You have bazel 0.19.2 installed. Please specify the location of python. [Default is /usr/bin/python]: Found possible Python library paths: /usr/local/lib/python2.7/dist-packages /usr/lib/python2.7/dist-packages Please input the desired Python library path to use. Default is [/usr/local/lib/python2.7/dist-packages] Do you wish to build TensorFlow with Apache Ignite support? [Y/n]: Apache Ignite support will be enabled for TensorFlow. Do you wish to build TensorFlow with XLA JIT support? [Y/n]: XLA JIT support will be enabled for TensorFlow. Do you wish to build TensorFlow with OpenCL SYCL support? [y/N]: No OpenCL SYCL support will be enabled for TensorFlow. Do you wish to build TensorFlow with ROCm support? [y/N]: No ROCm support will be enabled for TensorFlow.
Time to pay attention! Accept CUDA support:
Do you wish to build TensorFlow with CUDA support? [y/N]: Y CUDA support will be enabled for TensorFlow.
While I did have a symlink pointing /usr/local/cuda at my CUDA 9.0 install, I found that I had to specify the directory explicitly, as something in TensorFlow seemed unhappy with the symlink:
Please specify the CUDA SDK version you want to use. [Leave empty to default to CUDA 9.0]:Please specify the location where CUDA 9.0 toolkit is installed. Refer to README.md for more details. [Default is /usr/local/cuda]: /usr/local/cuda-9.0
cuDNN should be installed where TensorFlow is expecting, so let’s accept the default suggestions there:
Please specify the cuDNN version you want to use. [Leave empty to default to cuDNN 7]:Please specify the location where cuDNN 7 library is installed. Refer to README.md for more details. [Default is /usr/local/cuda-9.0]:
Alright, the next few steps are important:
Do you wish to build TensorFlow with TensorRT support? [y/N]: No TensorRT support will be enabled for TensorFlow.Please specify the NCCL version you want to use. If NCCL 2.2 is not installed, then you can use version 1.3 that can be fetched automatically but it may have worse performance with multiple GPUs. [Default is 2.2]: 1.3
Notice my selection of 1.3 as the NCCL version. For my machine, I am not trying to support SLI’d GPUs, so I’m fine with using the slower default for multiple GPUs. This is strictly a convenience choice on my part.
Here’s the most important option — configuring our CUDA compute capability:
Please specify a list of comma-separated Cuda compute capabilities you want to build with. You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus. Please note that each additional compute capability significantly increases your build time and binary size. [Default is: 3.5,7.0]: 3.0
Selecting 3.0 here gives us the CUDA Capability 3.0 support all of this has been for! The default options are fine for the rest of the selections:
Do you want to use clang as CUDA compiler? [y/N]: nvcc will be used as CUDA compiler. Please specify which gcc should be used by nvcc as the host compiler. [Default is /usr/bin/gcc]: Do you wish to build TensorFlow with MPI support? [y/N]: No MPI support will be enabled for TensorFlow. Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native]: Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]: Not configuring the WORKSPACE for Android builds. Preconfigured Bazel build configs. You can use any of the below by adding "--config=<>" to your build command. See tools/bazel.rc for more details. --config=mkl # Build with MKL support. --config=monolithic # Config for mostly static monolithic build. --config=gdr # Build with GDR support. --config=verbs # Build with libverbs support. --config=ngraph # Build with Intel nGraph support. Configuration finished
Alright, one last consideration, then we get to wait for an hour while TensorFlow builds! Bazel complains that TensorFlow has configuration info in a file that is no longer supported (remember the warning from earlier?) so let’s fix that:
cat tools/bazel.rc >> .tf_configure.bazelrc
Without further adieu, it’s time to actually compile:
# Compile TensorFlow - Prepare to wait a while :) bazel build --config=opt //tensorflow/tools/pip_package:build_pip_package # Build the TensorFlow python packages bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
And finally, let’s install (and test) the compiled TensorFlow:
# Install the TensorFlow python packages pip install --user /tmp/tensorflow_pkg/tensorflow-*.whl # Test TensorFlow cd && python >>> import tensorflow as tf >>> sess = tf.Session() 2018-12-14 10:52:25.604772: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1432] Found device 0 with properties: name: GeForce GTX 760 major: 3 minor: 0 memoryClockRate(GHz): 1.15 pciBusID: 0000:01:00.0 totalMemory: 3.94GiB freeMemory: 3.87GiB 2018-12-14 10:52:25.604809: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1511] Adding visible gpu devices: 0 2018-12-14 10:52:25.875258: I tensorflow/core/common_runtime/gpu/gpu_device.cc:982] Device interconnect StreamExecutor with strength 1 edge matrix: 2018-12-14 10:52:25.875291: I tensorflow/core/common_runtime/gpu/gpu_device.cc:988] 0 2018-12-14 10:52:25.875297: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1001] 0: N 2018-12-14 10:52:25.875445: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 3618 MB memory) -> physical GPU (device: 0, name: GeForce GTX 760, pci bus id: 0000:01:00.0, compute capability: 3.0)
If you see something similar to the tf.Session() output, then congrats — you’ve successfully built TensorFlow with CUDA Capability 3.0 support 😀
Merry computing!
References:
https://medium.com/@zhanwenchen/install-cuda-and-cudnn-for-tensorflow-gpu-on-ubuntu-79306e4ac04e